〒108-0023 東京都港区芝浦4-13-23 MS芝浦ビル2F
〒108-0023 東京都港区芝浦4-13-23 MS芝浦ビル2F
ブログ
日々これ精進
study & discipline
| 日 | 月 | 火 | 水 | 木 | 金 | 土 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
機械学習の勉強(O06S)
5年ほど前に機械学習のプロジェクトに参加していましたが、その時は機械学習のコードを書くことがなかったので、改めて勉強したいと思います。
今回の勉強では簡単に実装できると評判のライブラリpycaretを利用します。
開発環境は準備がそれほど必要ないブラウザベースのものを利用しpython(AIに適したプログラミング言語)でコードを書きます。
なお一つの処理は1,2行で書けますのでpythonの知識が無くても大丈夫かと思います。
機械学習ではデータを用意する必要がありますが、今回の環境では様々なサンプルが用意されており56種類のデータが利用できます。
・健康関連 (血液、がん、心臓病)
・金融/投資系 (銀行、金やダイヤモンドの価格)
・インターネット関連 (Wikipedia、Twitter、Facebook)
・Amazon、バイク、ポケモンなど
ちなみに、利用できるサンプルデータはインターネット上のアクセス可能な場所に全てアップロードされています。
サンプルデータの名前 (例:pokemon) を指定するとデータが確認できます。
あまりポケモンは詳しくないので応用が思い浮かばない… ので、今回は機械学習でありがちなアヤメのデータを利用します。
ここまでが準備段階です。
お題:アヤメのサイズから品種を特定する。
アヤメのサンプルデータには
・品種
・ガクの長さ/幅
・花びらの長さ/幅
が含まれています。
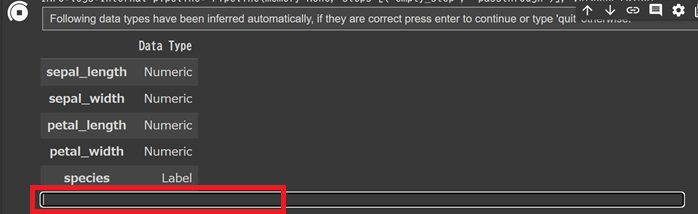
予測する項目を指定すると、その他の値も利用して学習を行います。
学習に利用するデータの割合も指定します。
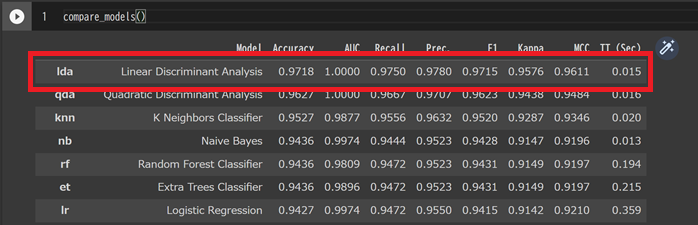
次に機械学習ライブラリの中で、最も精度が高いものを選びます。
それを利用した機械学習のモデルを作成します。
更にモデルの精度を上げるためにチューニングを施し予測精度のテストを行います。
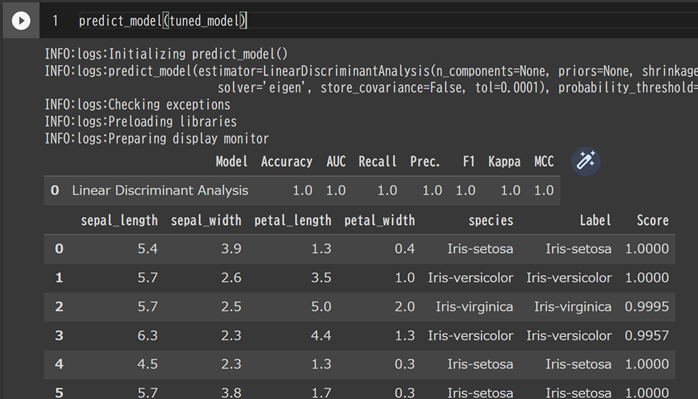
最後に完成したモデルを保存します。
保存したモデルは新しいデータに対する予測で再利用できます。
これで機械学習のモデルの作成とテスト、再利用まで完了ですが… 簡単すぎます。
世の中には機械学習のライブラリが数多くありますが、どれを選ぶのが最適かを見つけるためには、実際にそれぞれにライブラリで実行してみたりする必要がありました。
これがたった一行で終わります。
またライブラリを特定した後も、モデルのチューニングには山ほど時間がかかりますし、ライブラリの仕組みを理解しなければならず、勉強や試行錯誤に途方もない時間がかかります。
これも特に難しい数式を理解しなくても一行で終わります。
データは目的に合わせて用意する必要がありますが、以前と比較して少ないデータでも精度の高い学習効果が得られるように改良されているようですので、個人が収集したデータでも十分有用そうです。
多くのエンジニアが苦労する部分が着実に改良されていますね。
素晴らしいです。
ここまで簡単になっていますから、これから爆発的にAIのサービスが増えていきそうです。
2023年01月16日